G-avatar
实时通话数字人App
G-avatar是一款数字人app,不同于其他数字人产品,它更追求推理速度快,要求实时性,以便用户能够与数字人实时视频通话。用户上传一张照片或者一段视频后,算法会用它生成数字人,之后用户就可以跟数字人实时视频通话或者生成口播视频。
主要工作成果
-
训练出轻量化、可实时推理的视频改口型模型,相比原版wav2lip有以下改进:
- 输出分辨率从96增大到256
- 增加full face和face component的VGG loss训练损失项
- 增加嘴巴区域的GAN loss
- 将全脸的GAN loss的discriminator替换成multi-scale
-
推理加速与降本
- 使用tensorRT推理框架部署,显存从3.75GB降到1.58GB,推理耗时从每帧15毫秒降低到11毫秒
- 多线程并行处理,后处理耗时降低到原来的53%
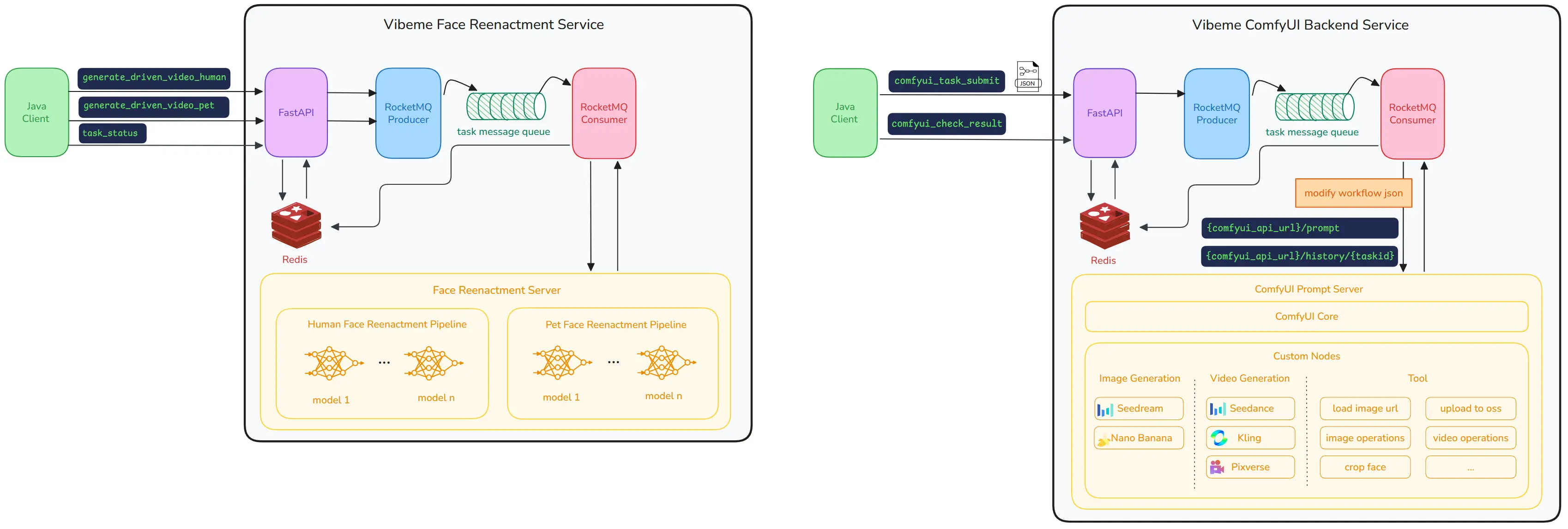
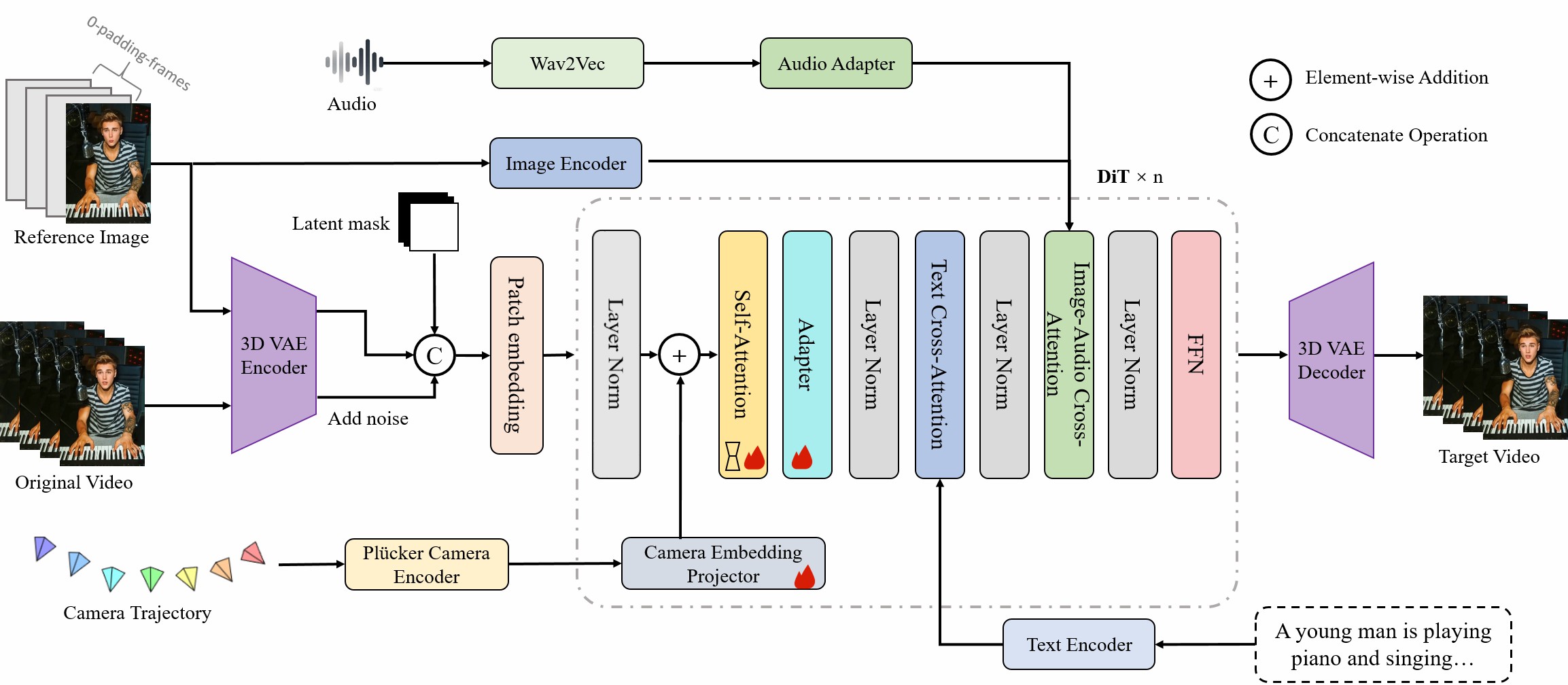
- 基于WebSocket和Agora RTC搭建了算法服务端架构
- 设计基于VAD的即时开麦机制,优化端到端延迟
- 调研了视频插帧、人像超分、co-speech相关算法,复现cyberhost的codebook attention。
App界面
创建数字人

数字人实时通话
口播视频
数字人实时通话架构图
算法效果演示
实时通话demo
口播视频